There have been times when you may need to take a list of strings and concatenate them together into a single string.
Think of a list of email address, concatenated by a semi-colon (;) like so:

As I’ve recently mentioned, loops can be slow … and the output messy, even with a simple “Append to string variable” action.
Just look at the output, double semi-colons (;;) where the blank values used to be … yucky!
clark.kent@dailypla.net;;lois.lane@dailypla.net;jimmy.olsen@dailypla.net;;perry.white@dailypla.netEven the Data Operation action Join, while easier/faster that the loop, is still messy!

I know what you’re thinking, it’s just a list of email addresses, double semicolons don’t really matter. True, but if you’re exporting the value to another system or doing some other processing on it, it may actually matter, especially if it’s some other value besides email addresses. Plus, nice-n-tidy clean strings are better to deal with. So …
XPath to the rescue!
Here’s how XPath can be used to make the output cleaner (and just as fast as the Join).
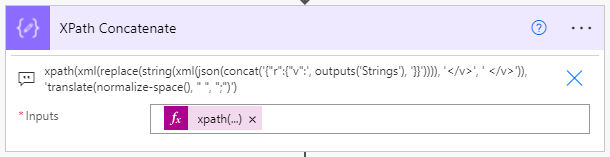
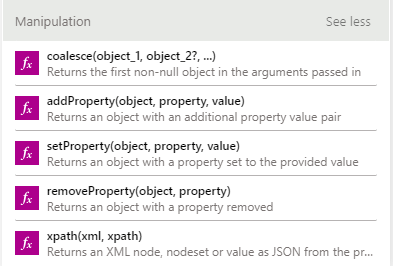
The key here is the combination of the translate(...) and normalize-space() XPath functions.
normalize-space() – grabs the text value from all nodes, reduces multiple spaces to a single space, then removes all beginning/trailing spaces from the final concatenated text value.
translate(...) – replaces the search character(s) with the specified character(s).
One thing to note here about the normalize-space() function. Since beginning/trailing spaces are removed, the text values are shoved together, like this:
clark.kent@dailypla.netlois.lane@dailypla.netjimmy.olsen@dailypla.netperry.white@dailypla.netShucks, now we don’t know where one value ends and the next begins.
To fix this, we simply inject in a trailing space after each value.
The XML will initially look like this
<r>
<v>clark.kent@dailypla.net</v>
<v>lois.lane@dailypla.net</v>
<v>jimmy.olsen@dailypla.net</v>
<v>perry.white@dailypla.net</v>
</r>and after this expression to inject the trailing space
replace(string(xml(json(concat('{"r":{"v":', outputs('Strings'), '}}')))), '</v>', ' </v>')the new XML will look like this (trailing spaces highlighted in blue)
<r>
<v>clark.kent@dailypla.net </v>
<v>lois.lane@dailypla.net </v>
<v>jimmy.olsen@dailypla.net </v>
<v>perry.white@dailypla.net </v>
</r>Here is the complete XPath expression and the output:
xpath(xml(replace(string(xml(json(concat('{"r":{"v":', outputs('Strings'), '}}')))), '</v>', ' </v>')), 'translate(normalize-space(), " ", ";")')
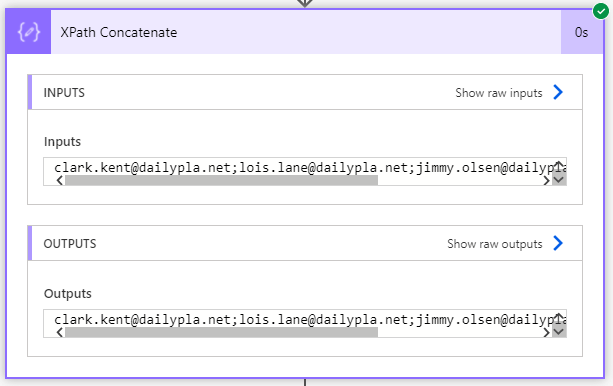
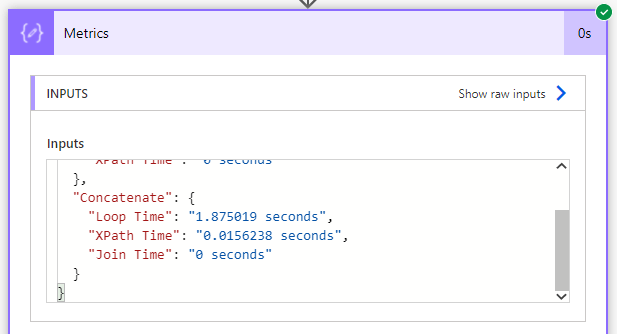
Lastly, to show you how well the XPath vs Join vs loop performs:
Happy coding!
Follow My Blog
Get new content delivered directly to your inbox.